React is a relative newcomer to the ever-shifting sands of javascript framework development. After skimming the tutorial, I was intrigued enough to give it a shot by rewriting a page of a small application with it.
Source
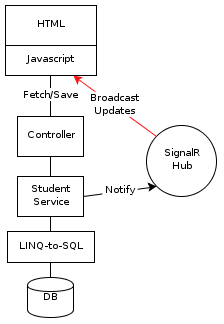
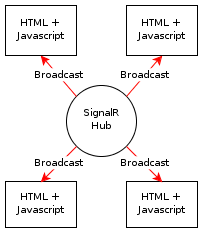
Root here, but most of the React code is in ui.jsx and StatusBox.jsx. The server code just implements a REST-like interface in Go language.
Demo
Health Monitor. The /detail/ page uses React. Compare it to the home/list page which uses handlebars for rendering.
TL,DR; I like it, much better than the typical disjointed javascript methods + templates pattern, and moreso than my limited experience with Backbone and Knockout. I’m itching to use React in my next project.
Most javascript binding frameworks face the same dilemma: Litter the view with logic or stitch together markup in the code. I’ve usually favored the former using tools like handlebars; React takes the latter approach, but not quite in the way you’d think.
Ever done this?
1 2 3 | |
It’s hard to tell if that’s even well formed, let alone correct.
React uses a syntax that permits a combination of HTML and Javascript which Facebook calls HTMLavascript and is enabled by <script type="text/HTMLavascript">.
If only. Actually, it’s called JSX and clever you probably wised up to the correct script type: text/jsx. Anyway, here’s an example taken from the aforementioned project:
1 2 3 4 5 6 7 8 | |
React can parse that into standard javascript on-the-fly during development or use a precompiled version for production.
Listed below are a few pros and cons I’ve gleaned along the way.
React Pros
-
JSX. The inline HTML syntax looks weird at first, but it’s concise and clean. Plus, the parser is amazingly precise with its error messages, and the accompanying suggestions are descriptive and accurate. JSX is still 90% javascript so there’s almost no interoperability problems with other javascript libraries. Just be aware it likes to control its own DOM so make sure plugins don’t screw with it radically. I read somewhere mounting to
<body>can cause hard to find bugs as many plugins add and remove there liberally. -
Client-side Model/state management. They say it’s the “V in MVC” but I find its real strength is in how it maintains a proper model. Typically I’d just map json to input boxes and pull them out at the right time. React enforces an internal state, and each change is reflected in that state. When the user is ready to commit a form, there’s no giant method extracting and converting data as the model is current in state.
-
Occupies the sweet-spot between functionality and shallow learning curve. It’s bite size enough to allow the developer to convert their code over in steps, testing it along the way, but carries enough features and structure to encourage the developer to create powerful and modular components.
-
Encapsulation. Each component encapsulates its own behavior and UI (and state if necessary, but less often than you’d think). For example, the markdown component manages its own toggle button behavior which controls whether to display rendered text or the input area. The components allow such good organization, I originally started with just an edit page + save button, but added in a view-detail step to all the components + edit and cancel actions in one big edit. After reviewing the code, fixing whatever syntax error messages came up (again, the parser is epic), the thing just worked. Not a huge deal in Java or Go, but Javascript??
-
Documentation is pretty darn good about walking you through a typical design scenario.
-
Lends itself to iterative refactoring. As I was developing, it was easy to see when a couple elements had outgrown their space and could be pulled into their own component or group.
React Cons
](http://www.xhroot.com/images/bucket_brigade2.jpg "ever-so-slight modification of [original](https://www.flickr.com/photos/app_rising/15186915191/in/photostream/)") ever-so-slight modification of original
ever-so-slight modification of original
-
Passing a function down the parent-child chain feels like a bucket brigade. Everyone gets their hands on it, only the last guy uses it.
-
External event interaction. I couldn’t find a way to fire React’s SyntheticEvent in a way that bubbles up to parents. The datetimepicker fires its own change event
dp.change; how do I notify an ancestor React element levels away to update the model?
Things learned
These points are taken from my limited experience in this particular domain. Different scenarios may invalidate some of this, YMMV.
-
Use React.addon.update to update state. It makes it easier to add a new object to state without having to preserve it explicitly in every
this.setState(). The query syntax for partial updating is pretty neat. -
I like the pattern of tacking extra data onto
SyntheticEventto pass info back to a parent. e.g., TextInput.handleChange -
Updating state kicks off a rerendering of all components under the parent. Here’s a typical flow:
- instantiate root React element
- fetch data async
- return with data
- put in state
Steps 2-4 incur a delay resulting in a brief flash of the 1st UI rendering, followed by a post-AJAX redraw. I use a PageBusy flag in state here to suppress the first render until data comes back.
Conclusion
Being able to reap rewards early from small integrations of React into a project makes it an easier sell to a team of varied skill level and time commitment. You could cherry pick a single widget on your page and convert it over for a test drive. The component architecture delivers well on code reuse. I’m not one to jump on every new javascript library like it’s the new hotness, but this one definitely has my attention.



](http://www.xhroot.com/images/rusty_gear_stevendepolo.jpg "photo by [stevendepolo](http://www.flickr.com/photos/stevendepolo)")